서론
어떤 콜백 함수가 값을 넘겨줄 때 SparseArray 타입으로 넘겨주는 것을 보고 SparseArray가 무엇이고 언제 사용해야 하는지에 대해 정리해보고자 한다. SparseArray에 대해 이해하는 과정에서 HashMap과 ArrayMap는 필수적으로 선행되어야 함을 알게 되었고, 이 과정에서 자료구조와 알고리즘에 해당하는 Map과 해시테이블에 대한 이해가 기반이 되어야 하기에 카테고리를 CS로 정하게 되었다. 최근 들어 안드로이드 개발에 있어 CS적 관점에 대해 많이 고민하고 있어서 흥미롭게 공부할 수 있었다.
맵(Map)

맵은 키(Key)-값(Value) 쌍을 하나의 데이터로 보고 이 쌍들을 저장하는 자료구조로 정의한다. 위 사진과 같이 키 234에는 Banana라는 값을 가지게 되고 키 382에는 Apple이라는 값을 가지게 된다.
해시테이블(Hash Table)

해싱이란 해시 함수(hash function)를 이용해 저장하고자 하는 키의 값을 저장하고자 하는 위치로 바꿔서 해당 위치에 값을 저장하는 것을 뜻한다. 그리고 각 위치를 버킷(bucket)이라고 표현한다. 위의 사진에서 보면 저장하고자 하는 키는 "John Smith"이고 값은 "521-1234"임을 알 수 있다. 키를 해시 함수에 넣어서 02라는 값을 얻게 되었고, 따라서 02 버킷에 "521-1234"를 저장하고 있다.
해시 테이블은 키 값을 알고 있으면 바로 값이 저장된 위치를 알아낼 수 있어 탐색, 삽입, 삭제 연산을 모두 일반적으로(해시 충돌의 경우가 있기 때문에 항상은 아니다.) O(1)의 시간 복잡도를 가진다는 장점이 있다. 반면 해시 함수를 통해 나온 값들이 골고루 분포되어 있지 않으면 한 버킷에 여러 값이 들어갈 수도 있고 빈 버킷이 많이 생기기 때문에 메모리 낭비가 생긴다는 단점이 있다. 특히 안드로이드 기기의 경우 2GB의 메모리를 가지고 있는 저가형 모델도 있기 때문에 메모리 관리가 중요시 된다. 이러한 부분을 보완한 것이 후술할 ArrayMap과 SparseArray이다.
버킷이 모든 키들의 경우의 수에 대응할 수 없기 때문에 당연하게도 하나의 버킷을 여러 키들이 가르키는 상황이 발생한다. 이러한 상황을 해시 충돌(Hash Collision)이라고 표현한다. 해시 충돌을 해결하기 위한 방법에는 대표적으로 Seperate Chaining과 Open Addressing이 있다.
Seperate Chaining

Seperate Chaining은 서로 다른 키들이 동일한 버킷을 가르키고 있을 때 키와 값 모두를 엔트리로 만들어 연결 리스트 형태로 저장하는 방식이다. 위의 사진에서 "John Smith"와 "Sandra Dee"는 동일하게 152번 버킷을 가리키고 있다. 키 "John Smith", 값 "521-1234"가 먼저 저장되어 있었기에 키 "Sandra Dee", 값 "521-9655"가 연결 리스트로 뒤에 저장됨을 알 수 있다. 이렇게 하나의 버킷에 여러 값이 들어 있는 것을 적재라고 표현한다.
Seperate Chaning으로 충돌 해결을 하면 적재량이 N이라고 했을 때 엔트리 삽입은 O(1), 탐색과 삭제에서 최악의 경우 O(N)의 시간 복잡도를 가지게 된다.
Open Addressing
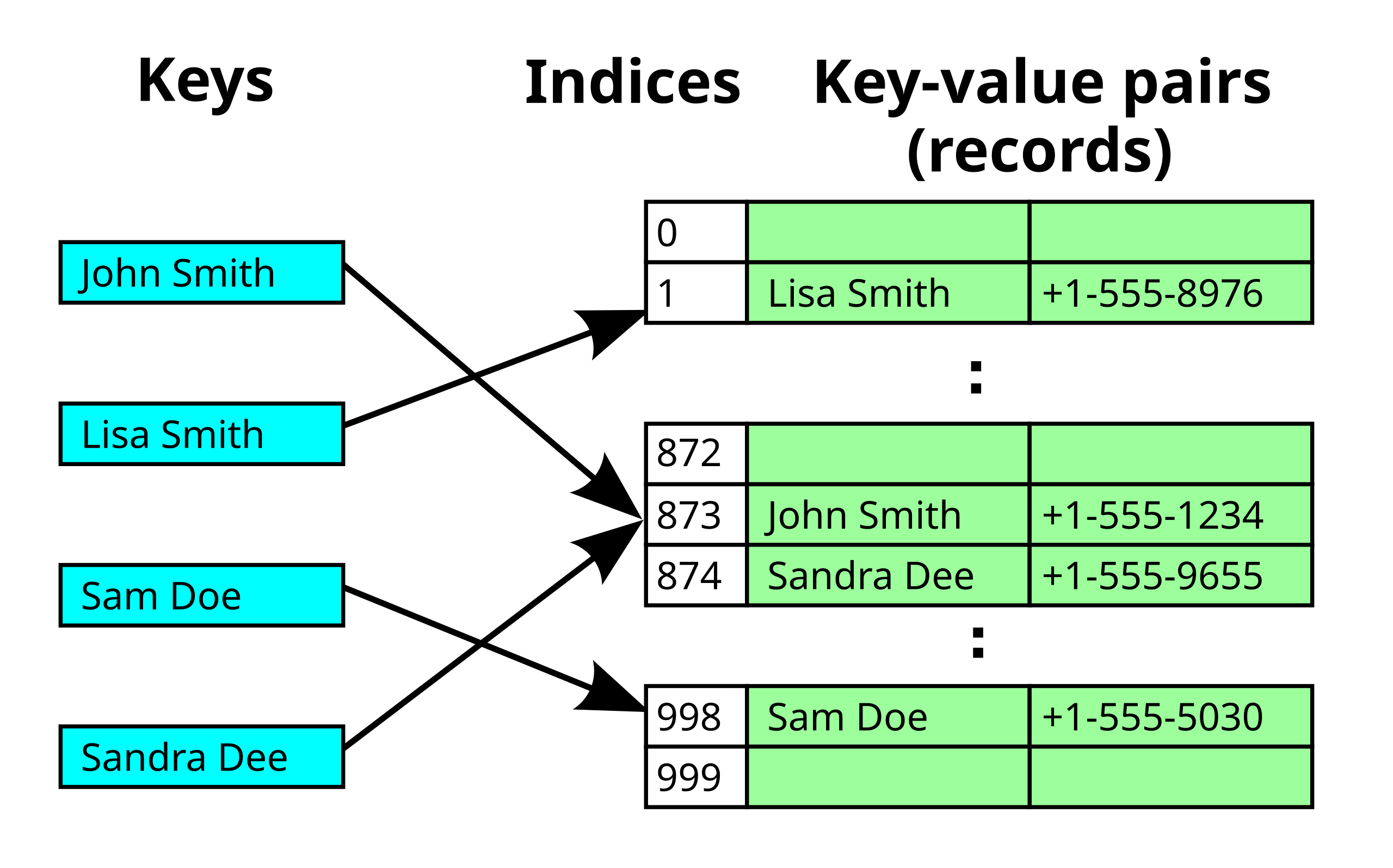
Open Addressing은 해시 충돌이 발생하면 비어있는 다른 버킷에 값을 저장하는 방식이다. "John Smith"와 "Sandra Dee"가 해시함수를 통해 동시에 873번 버킷에 값을 저장해야 하는 상황에서 "John Smith"가 먼저 저장이 되어 버킷에 값이 있는 상황이라면 "Sandra Dee"는 비어 있는 바로 다음 번호인 874번 버킷에 값을 저장하는 것이다.
비어있는 버킷을 찾아내는 것을 탐사(Probing)이라고 한다. 탐사에는 위의 상황과 같이 순차적으로 하나씩 다음 번호를 순회하는 선형 탐사(Linear Probing), 제곱 수 만큼 위치를 옮기면서 탐사하는 제곱 탐사(Quadratic Probing), 선형 탐사와 제곱 탐사로 인해 값들의 저장이 밀집되는 클러스터링을 방지하기 위해 다른 해시 함수를 적용한 이중 해싱(Double Hashing)이 있다.
여기까지가 공부의 시작이었던 SparseArray를 이해하는 데에 필요한 컴퓨터 과학 지식이다. 만약 안드로이드 개발자가 아니고 컴퓨터 지식에 대해서만 공부하는 것이 목적이라면 여기까지만 글을 읽어도 좋다.
HashMap
해시테이블은 일반적으로 O(1)로 데이터의 삽입, 탐색, 삭제가 가능하다는 큰 장점이 있기 때문에 대부분의 개발 언어에서는 해시테이블을 구현한 자료구조를 제공한다. Python에서는 dictionary, Java/Kotlin에서는 HashMap을 통해 해시테이블을 제공한다. Python은 Open Addressing, Java/Kotlin은 Seperate Chaining을 사용해 해시 충돌을 해결한다.
Seperate Chaining을 이용하면 하나의 버킷에 계속해서 많은 데이터가 쌓일 수 있다. 그리고 연결 리스트에 많은 데이터가 쌓일 수록 탐색, 삭제에서의 시간이 늘어날 가능성이 있다. 이러한 점 때문에 Java 8부터는 성능 개선을 위해 한 버킷 내에 데이터가 특정 개수(기본 값 8)를 초과하면 연결 리스트 형태가 아닌 Red-Black 트리 형태로 변환된다. 초과한 데이터 개수가 다시 특정 개수(기본 값 6) 이하로 낮아지면 트리 형태를 연결 리스트 형태로 변환한다.
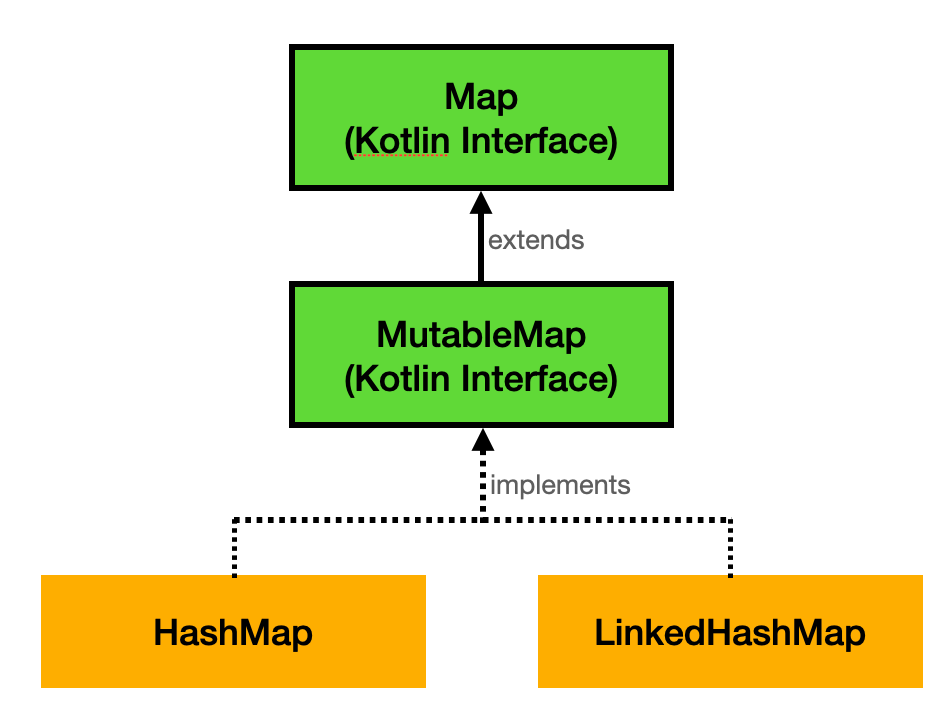
Kotlin에서는 Map과 MutableMap이라는 인터페이스를 제공한다. Map은 불변(Immutable)하고 MutableMap은 가변(mutable)이다. 이러한 Map 인터페이스를 구현하는 방식에 따라 HashMap과 LinkedHashMap으로 나뉜다. HashMap과 LinkedHashMap의 차이는 데이터 삽입 순서가 해시 테이블 상의 순서를 보장하느냐의 여부이다. HashMap은 이를 보장하지 않고 LinkedHashMap은 이를 보장한다. 이 글에서는 해시테이블의 원리를 구현한 HashMap을 중점적으로 살펴볼 것이다.
HashMap에서는 총 버킷 수를 Capacity라고 표현하며, 부하 계수(LoadFactor)라는 임계점이 존재한다. (사용 중인 버킷 수) / (Capacity)가 부하 계수를 초과하면 리사이징이 일어나며 Capacity가 2배 증가한다. HashMap 객체를 처음 생성하면 기본적으로 16의 Capacity와 0.75의 부하 계수가 주어진다. 따라서 HashMap에 값이 계속 삽입되어 16개의 버킷 중 13개가 사용되는 순간 Capacity는 32로 늘어나게 된다. 크기가 늘어난 HashMap은 재해싱 과정이 일어나 추가적인 계산이 필요하다.
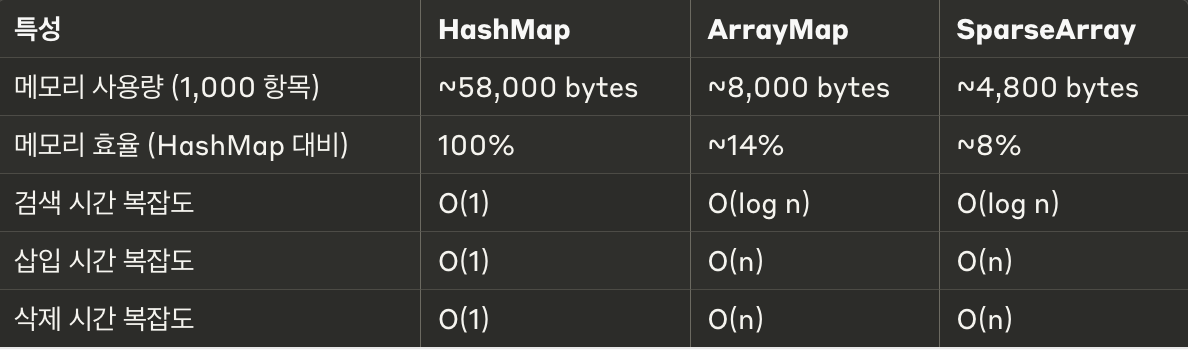
여기서 우리가 주목해야 할 점은 HashMap을 사용하면 메모리를 차지하는 빈 버킷이 항상 존재한다는 것이다. 앞서 말한 것처럼 안드로이드 기기는 비교적 메모리가 작기 때문에 불필요한 메모리 차지를 최대한 줄여야 한다. 따라서 안드로이드에서는 ArrayMap과 SparseArray를 제공한다.
ArrayMap
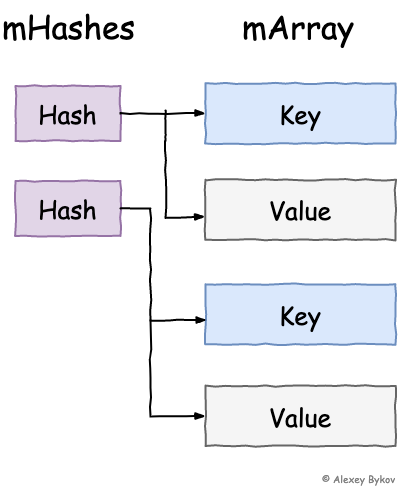
이름에서 굉장히 Kotlin Collection의 자료구조 중 하나일 것 같은 냄새가 폴폴 남에도 불구하고 ArrayMap은 안드로이드 SDK에서 제공하는 자료구조이다. 선언만 해도 16개의 버킷이 생성되는 HashMap과 달리 ArrayMap은 mHashes(기본 크기 4)와 mArray(기본 크기 8)라는 두 개의 작은 배열이 생성된다. mHashes 배열에는 키의 해시코드를 저장하고 mArray에는 키와 값을 저장한다.
기본적으로 16개의 버킷이 생성되고, 부하 계수를 초과하면 버킷의 수가 증가해 불필요한 메모리를 차지하는 HashMap과 달리 ArrayMap은 실제로 사용하는 데이터의 개수만큼 객체의 크기가 조절(추가 및 삭제)되기 때문에 메모리 측면에서 보다 효율적이라는 이점이 있다. 또한 HashMap은 리사이징이 되면 재해싱 과정이 필요하지만 ArrayMap은 내부적으로 System.arrayCopy()를 이용해 크기가 늘어난 배열에 값을 복사하는 과정만 필요하기 때문에 HashMap에 비해 리사이징 속도가 빠르다.
ArrayMap에서 데이터를 삽입하려는 경우, 먼저 키의 해시 값을 mHashes 배열에 저장해야 한다. 탐색 과정에서의 시간 복잡도를 줄이기 위해 mHashes 배열에 해시 값을 삽입하고 탐색할 때에는 이진 탐색을 사용한다. 따라서 mHashes 배열은 항상 정렬되어 있어야 한다. 이진 탐색을 이용하더라도 HashMap의 삽입 / 탐색 시간복잡도인 O(1)보다는 느리다는 단점이 있다. ArrayMap에서는 해시 충돌이 일어난 경우, Open Addressing의 선형 순회를 사용한다. 다만 위에서 설명한 다음 인덱스를 찾는 선형 순회가 아닌 이전 인덱스와 다음 인덱스를 모두 찾는 양방향 선형 순회를 이용해 해시 충돌을 해결한다.
ArrayMap은 HashMap에 비해 메모리는 효율적으로 사용하지만 이진 탐색을 이용해 삽입 / 탐색 / 삭제 연산을 수행하기 때문에 데이터의 크기가 커질수록 계산 속도가 느려진다는 단점이 있다.
SparseArray
SparseArray 역시 ArrayMap과 같이 안드로이드 SDK에서 제공하는 자료구조이다. 기본적인 구조는 ArrayMap과 동일하다. 다만 SparseArray의 키는 항상 Primitive 타입이다. 키를 항상 Primitive 타입으로 만든 것은 오토 박싱(Auto Boxing)으로 발생하는 불필요한 메모리 사용을 방지하기 위함이다.
JDK 1.5부터 오토 박싱이 적용되어 Primitive 타입을 Wrapper 클래스 변수에 대입만 하면 자동으로 박싱이 되는데, Wrapper 타입은 Primitive 타입보다 메모리를 많이 사용한다는 단점이 있다. (Primivite 타입인 int는 4Btye, Wrapper 타입인 Integer는 16 byte이다.)
HashMap과 ArrayMap의 키와 값은 모두 객체여야 하기 때문에 Primitive 타입을 사용하더라도 오토 박싱으로 인해 Wrapper 객체가 생성될 수 밖에 없는 구조이다. 반면 SparseArray는 이러한 오토 박싱을 피하도록 설계되었기 때문에 키를 항상 기본 타입인 int 타입을 사용한다. (값은 여전히 객체여야 하기 때문에 오토 박싱이 일어난다.) 따라서 키를 정수로 사용하고 데이터의 개수가 많지 않은 경우라면 SparseArray를 사용하는 것이 가장 좋은 선택으로 보인다.
메모리 효율성 및 시간 복잡도 비교
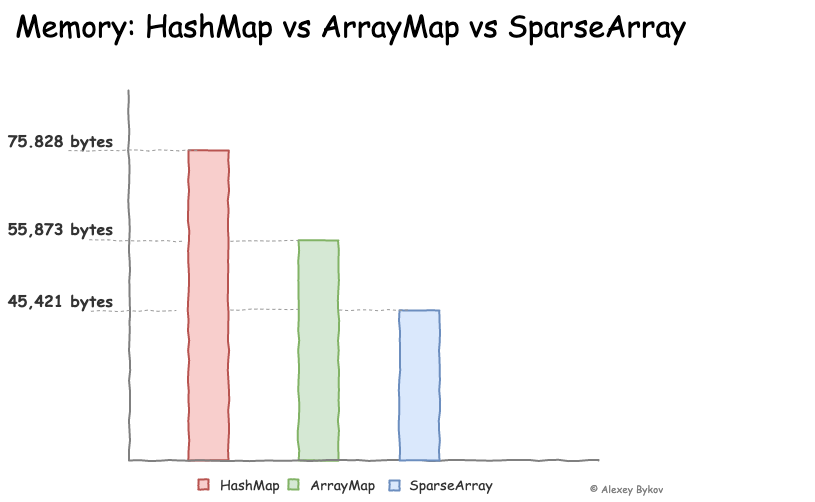
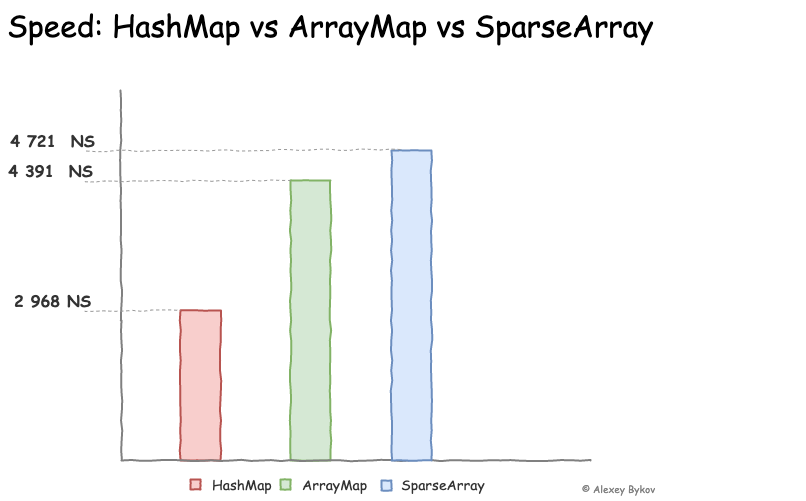
HashMap, ArrayMap, SparseArray 중 하나를 선택해야하는 것은 개발자의 몫이다. 어떤 데이터를 다루고 있는지 문맥을 파악하고 해당 데이터의 개수가 어느 정도 될지 판단해야 하며, 빠른 연산이 중요한 작업인지를 결정해야 한다. 아래 그래프는
Alexey Bykov 라는 개발자가 실험하고 정리해둔 자료이다. 데이터 크기를 1000으로 하고 100번의 읽기 작업으로 테스트한 결과라고 한다. 일반적으로 ArrayMap / SparseArray 는 1000개 이하의 데이터 크기에서 HashMap에 비해 최적의 성능을 보인다고 한다.
'Computer Science' 카테고리의 다른 글
| [CS, Android] 앱은 어떻게 만들어질까? (0) | 2025.02.11 |
|---|
