서론
프로젝트에 신규 피쳐가 추가될 때마다 설계를 고민하게 되면서 자연스럽게 아키텍쳐에 대한 고민도 함께 하게 된다. 현재 회사 프로젝트의 전반적인 아키텍쳐는 구글 권장 아키텍쳐이다. 하지만 최근 맡게 된 피쳐의 모듈은 클린 아키텍쳐로 구성하는 경험을 하게 되었는데, 각 아키텍쳐를 경험해보았을 때 주관적인 견해를 기록해보려고 한다.
안드로이드 권장 아키텍쳐
친절하게도 구글은 안드로이드를 개발할 때 이런 아키텍쳐를 쓰길 바란다며 공식문서에 상세하게 나와있다. 물론 개발 요구사항이나 프로젝트의 규모에 따라 이를 수정할 수도 있다. 아키텍쳐는 말 그대로 하나의 건축 양식을 정하는 것일 뿐, 정답은 없다고 생각한다.
아래 그림을 통해 구글 권장 아키텍쳐에 대해 핵심적인 부분을 살펴볼 수 있다.

구글 권장 아키텍쳐는 UI Layer와 Data Layer가 나뉘며 Domain Layer는 선택 사항이다. UI Layer와 Data Layer가 나뉘는 이유에 대해서 알아보자.
UI는 앱의 생명주기와 안드로이드 시스템에 밀접하게 연관되어 있다. 즉 메모리 이슈와 같은 모종의 이유로 OS가 앱의 프로세스를 종료해버리면 UI는 삭제된다. 하지만 데이터는 삭제되면 안된다. 데이터는 말그대로 정보이기 때문에 앱의 프로세스가 종료된다고 사라져버려서는 안되는 영구적인 모델이 되는 것이 이상적이다.
또한 구글은 새로운 데이터 타입이 정의되면 Single source of truth(SSOT) 원칙을 반드시 적용해야한다고 말한다. SSOT는 하나의 데이터의 변경은 하나의 통로를 통해서만 수정되어야 하고 불변으로만 데이터를 노출해야 한다는 것이다. 이를 지키면 데이터의 변경이 일어나는 지점을 단일화시킬 수 있고, 데이터를 보호할 수 있다. 변경이 한 곳에서만 일어난다는 것은 이슈가 발생해도 추적이나 수정이 쉬워 유지보수 비용이 적게 드는 장점으로 이어진다.
구글 권장 아키텍쳐는 상태(State)와 이벤트(Event)의 흐름이 단방향이라는 것이다. 구글에서는 이를 UDF(Unidirectional Data Flow)라고 부른다. 여기서 상태는 주로 데이터에 의해 결정되는 것으로 공식문서에서 또한 상태와 데이터를 혼용해서 사용한다. 따라서 데이터는 흔히 서버에서 가져오거나 로컬 저장소에서 가져오게 된다. 즉, Data Layer를 시작으로 Domain Layer를 거쳐(Domain Layer가 존재한다면) UI Layer로 넘어와 화면에 보여지게 된다. 이벤트는 사용자의 클릭과 같은 것으로 UI Layer에서 발생하게 된다. 이벤트로 인해 발생되는 결과로 인해 데이터가 변경되면 이는 Domain Layer(Domain Layer가 있다면)를 거쳐 Data Layer로 이동하게 된다.
클린 아키텍쳐
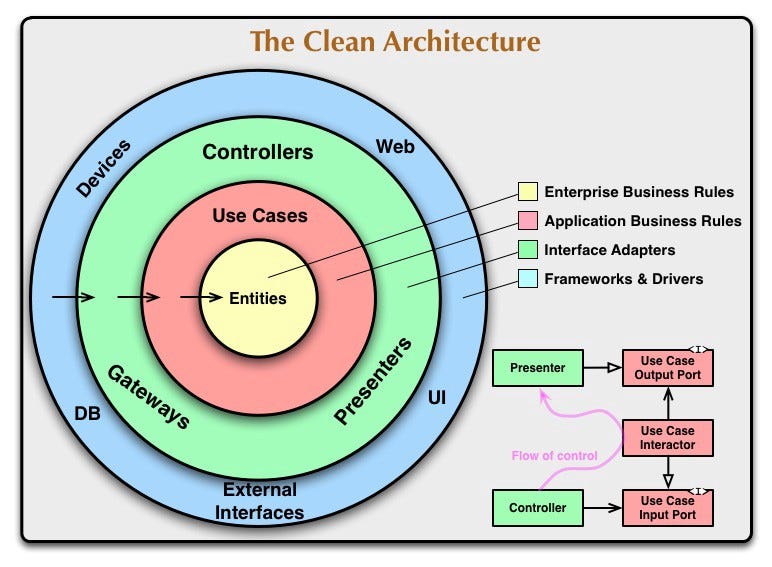
클린 아키텍쳐는 안드로이드에만 국한되는 아키텍쳐가 아니라 로버트 C. 마틴이라는 개발자가 만든 소프트웨어 설계 개념이다. 원의 안쪽으로 갈수록 고수준의 소프트웨어를 의미한다. 비즈니스 도메인의 모델이 동심원 가장 안쪽에 있는 노란색 원의 Entities에 해당한다. 클린 아키텍쳐의 가장 중요한 규칙은 종속성 규칙, 즉 경계를 구분 짓는 것이다. 화살표를 보면 알 수 있듯이 종속성은 원의 바깥에서 안쪽으로 작용한다. 즉, 내부 원 안에서는 절대 외부 원을 알아서는 안된다.(의존성을 가지면 안된다는 뜻이다.) 또한 외부 원에서 내부 원에 영향을 주면 안된다고 하는데, 이는 의존성은 가지지만 내부 원에 있는 모델의 구조나 함수 등에 영향을 주면 안된다는 뜻인 것 같다.(원문 : We don’t want anything in an outer circle to impact the inner circles.)
클린 아키텍쳐를 안드로이드에 적용하기 위해서는 어떻게 해야 할까? 대중적으로 노란색 원인 Entities와 빨간색 원인 UseCases를 묶어서 Domain 모듈로 만든다. Entities와 UseCases는 핵심 비즈니스 로직과 모델만을 다루고 있기 때문에 Domain 모듈은 순수하게 Java/Kotlin으로 이루어지는게 이상적이다. 즉, Android 의존성이 없어야 한다. 초록색 원과 파란색 원에는 UI, DB와 같이 UI Layer와 Data Layer에 해당하는 요소들이 들어가 있다. 따라서 UI Layer도 Domain Layer를 의존하고 있고, Data Layer도 Domain Layer를 의존하고 있는 상황이 된다.
UI Layer → Domain Layer ← Data Layer
그런데 우리는 UI Layer에서 발생한 이벤트로 파생된 결과를 Data Layer로 보내 서버나 로컬에 저장하기도 해야 하며, Data Layer에서 받은 데이터를 UI Layer에서 받아서 화면에 표시해주기도 해야 하는데, 의존성의 방향이 모두 Domain Layer를 향하고 있으니 문제가 된다.
이를 해결하기 위해 로버트 C. 마틴은 Dependency Inversion Principle이라는 그 유명한 SOLID 중 하나인 의존 관계 역전 원칙을 사용하라고 한다. 아래 그림과 같이 Java나 Kotlin에서는 인터페이스를 이용해 의존 관계를 역전시킬 수 있다.

Domain Layer에서는 인터페이스를 통해 추상화하고 Data Layer에서 인터페이스를 구현한다. 이렇게 하면 데이터의 흐름은 UI -> Domain -> Data로 유지가 되면서 종속성은 UI와 Data 모두 Domain을 바라보는 형태가 되며 클린 아키텍쳐의 동심원 구조가 지켜진다.
개인적인 생각
두 가지 아키텍쳐를 모두 적용해보았을 때 느낀점은 다음과 같다.
가장 큰 차이는 Domain Layer에 있다고 느꼈다. 안드로이드 권장 아키텍쳐의 경우 Domain Layer는 옵셔널한 것이다. 따라서 코드를 작성하는 사람에 따라 Domain Layer를 사용해 구현할 수도 있고, 사용하지 않고 구현할 수도 있다. 미리 약속을 정하지 않았다면 모델이 파편화될 수 있다. 어떤 사람은 UI 모델에서 바로 DTO 모델로 변환해서 통신을 하기도 하고, 어떤 사람은 Domain 모델을 이용해 매핑하기도 한다. Domain 모델이 필수가 아닌 경우에는 유연하고 빠르게 대응할 수 있다는 장점이 있지만 일관되지 않게 사용한다면 처음 코드를 접한 사람에게는 혼란을 초래할 수 있다.
특히 외부 SDK 연동 작업을 하는 경우 Domain Layer는 필수적인 요소라고 판단했는데, 같은 기능을 하는 SDK여도 SDK 제조사마다 정의한 데이터 모델이 다르기 때문에 이를 하나의 앱에서 관리하기 위해서는 Domain 모델을 만들어 매핑하는 것이 확장성과 유지 보수 측면에서 유리하다고 느꼈다. 이러한 케이스에서는 클린 아키텍쳐의 특징을 활용하는 것이 더 적절하다고 생각한다.
반면 클린 아키텍쳐에서는 Data Layer의 모든 객체를 인터페이스로 추상화하도록 만들어야만 의존성이 유지되기 때문에 모듈러 아키텍쳐를 사용하는 프로젝트의 경우 모든 모듈이 클린 아키텍쳐로 통일되면 개발하기 더 편할 것 같다고 느꼈다. 또한 익숙함의 차이일 수도 있지만 데이터의 흐름은 Domain에서 Data인데 의존성은 Data가 Domain을 알고 있다는 것 또한 사고의 과정이 한 번 더 들어가는 느낌이었다.
클린 아키텍쳐의 Domain Layer는 순수한 Java/Kotlin으로 이루어져야 한다고 말하는데, 이는 Domain Layer의 테스트 코드 작성과 더불어 Domain Layer만 따로 모듈화하여 핵심 기능은 동일하지만 요구사항이나 엔드포인트가 다른 어플리케이션에 적용하기 위함이 있으므로 필요에 따라 목적에 특화된 아키텍쳐를 선택하면 될 것 같다.